


Introduction
This article begins from the intensively studied question of whether the presence or absence of answer options for expressing a lack of opinion, such as a “don’t know” option (DK-O; e.g., Alwin and Krosnick 1991; Andrews 1984; de Leeuw, Hox, and Boevé 2016; O’Muircheartaigh and Helic 2000) or a neutral/moderate opinion, such as a midpoint (e.g., Baka, Figgou, and Triga 2012; Garland 1991; Hurley 1998; Moors 2008; Sturgis, Roberts, and Smith 2014), affects the quality of data on attitude. Researchers agree on some points but follow different convictions or have different preferences in other aspects. Reasons for respondents choosing a DK-O or middle category (MC) may be manifold and not necessarily due to a lack of a neutral/moderate opinion.
Krosnick and Fabrigar (1997) already summarized five explanations for choosing a DK-O, apart from a lack of knowledge, namely ambivalent attitudes when a MC is missing, neutral views when a neutral response is missing, inability to understand the question, uncertainty about the meaning of the scale points, and satisficing. Based on contradictory results of previous studies (conducted by different researchers, mainly in the 1980s and 1990s), Krosnick and Fabrigar (1997) conclude that omitting no-opinion options for attitude questions would lead to more reported “real” attitudes rather than apparently false substantive answers by opinionless respondents. Nevertheless, contradictory findings (DeCastellarnau 2018) indicating that a DK-O influences or does not influence data quality have continued to be made—while some researchers still argue that a DK-O leads to incomplete, less valid and less meaningful data, others find no support for these effects.
In contrast, the reason for choosing a midpoint might be a neutral position (bipolar scale) or a moderate opinion (unipolar scale) (e.g., Krosnick and Fabrigar 1997), but also minimizing effort by satisficing (Krosnick 1991). Therefore, regarding the inclusion of a MC, Krosnick and Fabrigar (1997) point out, “Evidence on validity is mixed, and the theory of satisficing suggests that including midpoints may decrease measurement quality” (p. 148). Menold and Bogner (2016) agree with this, based on several findings from past and current studies. However, they point out that “most researchers recommend that a middle alternative should be offered in order to prevent respondents who have a moderate or neutral opinion from having to use an alternative category, thereby systematically distorting the data” (p. 4). Nonetheless, Streiner, Norman, and Cairney (2015) argue that the decision between an even or odd number of categories (the latter implies a sort of midpoint) within a unipolar scale is of little impact.
Briefly, arguments for omitting or providing a MC or/and a DK-O are inconsistent.
Ultimately, the question remains unanswered as to whether a MC and/or a DK-O should be offered or omitted when measuring attitudes. Figure 1 illustrates plausible recommendations which may guide researchers’ decisions.
Both justifications presuppose that the researcher is able to assess the respective target group accordingly, although this is not always the case. This article aims to test an alternative approach. It empirically investigates the response behavior in terms of preferences for a MC or a DK-O when one or both of these options are present; the decision for or against a MC and/or a DK-O may be based on the target groups’ reaction to various response scales but, is nevertheless, most probably a compromise.
Response Behavior: Methodological Considerations
Cognitive response theory (Tourangeau 1984) forms the starting point for the following considerations. Answering a question takes four steps: (1) comprehension of the question, (2) recall and retrieval of relevant information, (3) judgment and assessment based on the retrieved information, and (4) reporting an answer by linking it to the response category provided.
With reference to the response theory, respondents’ knowledge about the topic in question can be assumed to be relevant to their ability to form an opinion and answer a question on attitudes properly. For instance, Lemert (1992) states that “popular knowledge can be so low about so many things that measuring preferences without first measuring knowledge can produce essentially meaningless percentages” (p. 41). Therefore, respondents might face difficulties when they are inexperienced. They may not have enough knowledge (not be able to recall/retrieve relevant information) that is helpful in order to form an opinion. Furthermore, respondents who have a moderate opinion may not be able to take a clearly positive or critical position. They must find an alternative solution when the required response category is not present. Accordingly, O’Muircheartaigh and Helic (2000) suggest that a midpoint should be provided in order to reduce measurement error, since people in this category may make random choices if there is none. In both cases (when respondents lack experience or have moderate opinions), if the ideal answer category (a DK-O or MC) is missing, a somewhat sufficient solution will instead be found—not least because, as experience shows, respondents usually try to fit into the given answer categories and avoid item nonresponse. In this context, “somewhat sufficient” means the occurrence of certain response sets as a consequence of the scale, for example, positive answers instead of the “right ones” when a DK-O or MC are missing.
Figure 2 shows respondents’ different response strategies—derived from previously mentioned preliminary considerations —which vary according to the given scale format.
At first glance, an uneven scale including a DK-O promises to be a suitable version on most occasions. However, the impact of most respondents’ knowledge on the topic is also assumed to be relevant for the outcome.
For instance, if the respondents generally have experience in the topic, the presence of a DK-O makes less sense. Conversely, there might be a higher risk of response distortion, which was previously mentioned, if respondents have little or no experience of the survey topic, but there is no DK-O. In that case (see Krosnick and Fabrigar 1997), systematic response patterns that change the frequency distribution of the result are more likely to occur than random and thus equally distributed responses. A tendency towards positive (agreeing) answers would be a plausible reaction. If this is true, the following Hypothesis One is supported:
H1: The absence of a DK-O increases the share of positive response categories.
Furthermore, if respondents are able to clearly agree or disagree with specific statements, the presence of a MC might be pointless. Conversely, respondents with a moderate attitude might have trouble coping with the task of taking a side. In that case, as previously argued, systematic response patterns that change the frequency distribution of the result are more likely than random and equally distributed responses. If this is true, the following Hypothesis Two is supported:
H2: The absence of a MC increases the share of positive response categories.
The verification or refutation of the previously mentioned hypotheses might serve as guiding factors for the decision for or against a response scale, as shown later.
Data and Methods
Data
Data were collected by means of an online survey (optimized for smartphones) dealing with student participation at a university in Austria. It can be reasonably assumed that this survey/topic is appropriate for the intended analyses, since the students’ engagement and therefore insights into university policies differ. For example, in 2017, and the years before that[1], less than 25% of the students took part in the election for the students’ union in Austria. Therefore, it is safe to assume that the sample consists of students with more experience (voters) and others with less experience (nonvoters).
In total, 17,491 students were contacted via email. Almost every student was contactable by email. Of them, 2,483 (14.2%) responded to the invitation, and 1,923 (11%) answered at least one question. In total, 7.3% (n=1,282) of the invited students finished the survey by reaching the final page. Previous surveys have shown that this is a typical response rate for the target group. Nonetheless, the students who dropped out are excluded in order to avoid biased results based on item nonresponses caused by the time at which they dropped out. Consequently, the following analyses are based on 1,282 cases.
Experimental Design
In order to explore the students’ preferences depending on the availability of a MC and/or DK-O, an experimental design was used based on a unipolar scale. This is because a unipolar scale has the advantage of higher reliability (Alwin 2007).
Nonetheless, the researcher has to decide whether a moderate position (middle category) and/or a “don’t know” option is needed. Therefore, all invited students were randomly assigned to one of four conditions. The answer format of the rating scales provided to each group, concerning three sets of items, differed due to the absence of a DK-O and/or a MC. In order not to overtax the respondents, a moderate number of response categories was chosen: four categories excluding a “don’t know” option (4c/4c+mc) and five including it (4c+dk/4c+mc+dk). This restriction was selected because Alwin (2007) reports “the superiority of four- and five-category scales for unipolar concepts” (p. 196).
Table 1 shows that the survey population (after data cleansing) was divided into four comparably sized groups of about 23% to 26%. Accordingly, the dropout rates did not statistically significantly differ (chi2=4.412; p=0.220) based on group assignment.
Extracts of the questions and the given answer categories are included in the appendix. At this point, it should be mentioned that only the endpoints were clearly labelled as “very satisfied” and “not satisfied at all.” To avoid “face-saving don’t knowers,” the MC was tagged with a face emoji (see figure A-1 in the appendix) in the case of two small sets of items and not tagged at all in the case of one large set of items.
Results
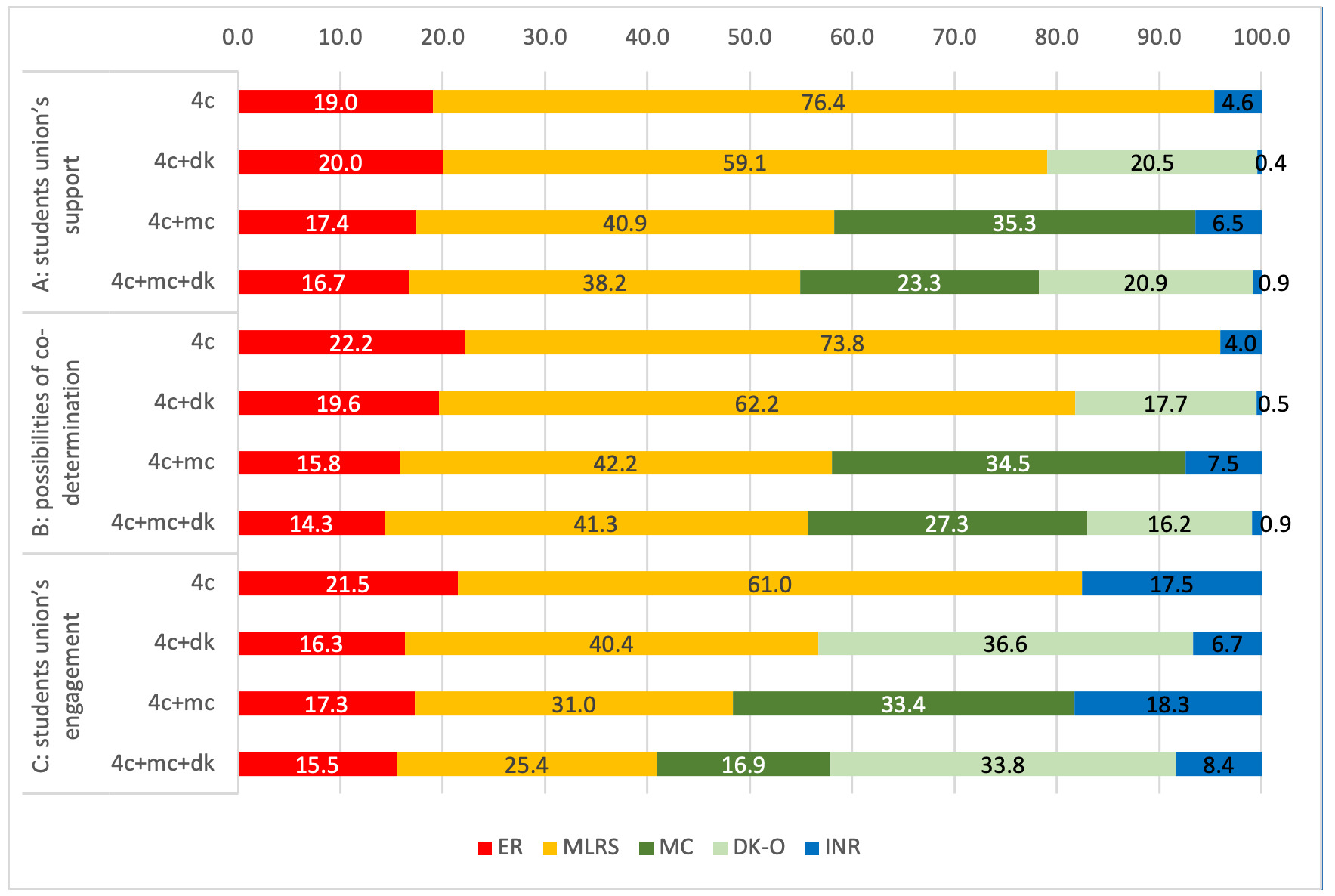
Descriptive results based on the group affiliation previously mentioned (Table 1) are shown in Figure 3. More precisely, the average proportion of extreme responses (ERs; e.g., “very satisfied” and “not satisfied at all”), of chosen middle categories (MCs), of mild response styles (MLRSs, response categories next to the ER categories), of chosen “don’t know” options (DK-Os), and of item nonresponses (INRs), are presented per set of items. It is clear that offering a MC in addition to a DK-O (4c+mc+dk vs. 4c+dk) did not essentially affect the proportion of participants that chose a DK-O, showing a decrease of about one to three percentage points. Conversely, offering a DK-O in addition to a MC (4c+mc+dk vs. 4c+mc) decreased the proportion of participants that chose a MC by about 7 to 17 percentage points, and reduced the proportion of participants that chose a INR by about six to ten percentage points. Moreover, the proportion of participants that chose a MLRS decreased more and more if a DK-O, a MC or a combination of the two was available. This was similarly true for ERs, but in a limited way.
__differentiated_by_group_aff.png)
The calculation of the average number of MCs and DK-Os chosen (see Table 2) for all three sets of items confirms the outcome presented previously. The risk or chance of choosing a MC was almost twice as high if no DK-O was available compared to one being available. On average, seven (4c+mc) or four (4c+mc+dk) out of 20 possible options were chosen. The difference is statistically significant. On the other hand, the level of risk or chance of choosing a DK-O did not depend on whether a MC was available. On average, about six MCs out of 20 possibilities were selected.
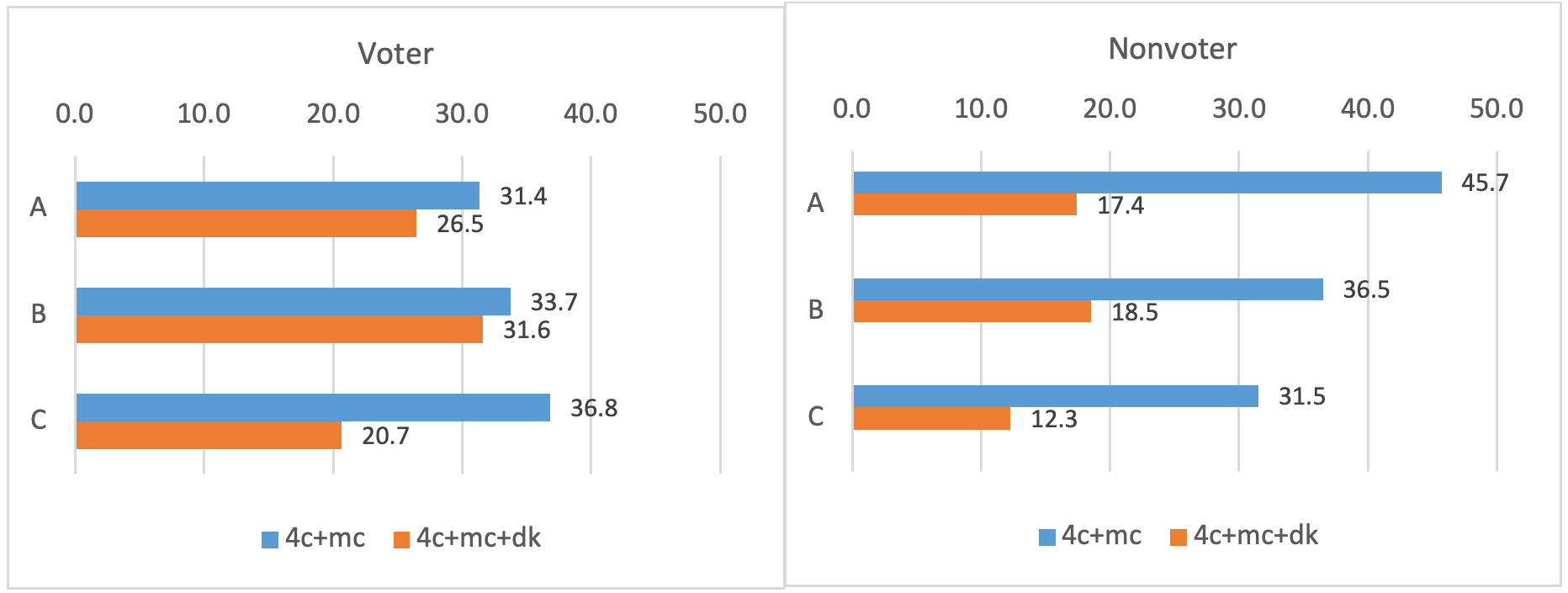
Figure 4 illustrates that choosing a MC depended on the respondents’ experience with the subject of the survey, “student participation”, which was measured by participation in the elections of the student representatives (voter vs. nonvoter). Although the proportion of voters and nonvoters that chose a MC was reduced when a DK-O was available, the extent to which this occurred varied. The difference was much smaller among voters (with just one statistically significant result) than among nonvoters (with three statistically significant results). In contrast, the proportion of voters and nonvoters that chose a DK-O was independent of whether a MC was present—only small, statistically insignificant differences were observed (see Figure 5).
__depending_on_the_availability_of_a_d.png)
__depending_on_the_availability_of_a.png)
But what does this mean for the outcome of the survey? Table 3 should give an answer to this question, as it presents the frequency distribution of the three sets of items (A, B, C). In order to detect differences in the distribution of the responses, the “don’t know” and/or “moderate” responses were treated as missing.
Based on item sets A and B, the presence of a DK-O (comparing 4c vs. 4c+dk and 4c+mc vs. 4c+mc+dk) did not statistically significantly change the respective share of responses to other categories, when the DK-O responses (as well as the MC responses) were set as missing. In these cases, a tendency for positive responses could not be detected. This means the students might have enough knowledge to form an opinion regarding the question if they are forced to. However, item set C reveals two statistically significant differences (C: i vs. ii). The respective questions probably require greater insight. In this case, the slightly positive answers “somewhat satisfied” decreased while the slightly negative answers “somewhat dissatisfied” increased. However, H1 is refuted. The presence of a MC (comparing 4c vs. 4c+mc and 4c+dk and 4c+mc+dk) did change the share of several answer categories if the MC (as well as the DK-O) responses were set as missing. For two item sets (sets A and C), this procedure mainly increased the proportion of “very satisfied” respondents and mainly reduced the proportion of “somewhat dissatisfied” respondents, but also statistically significantly (but only partly) reduced the proportion of “not at all satisfied” respondents. Item set B was only marginally affected. This means that the students showed systematic response patterns (negative responses were reduced) depending on the availability of a MC. H2 is verified.
However, excluding respondents who showed systematic responses might not be an option—as this would generally distort the data collected. Accordingly, alternative ways are discussed below.
Conclusions and Recommendations
Scale-sensitive response behavior was empirically tested in terms of preferences for a MC or DK-O when answering questions of attitude. The results suggest that respondents who choose a DK-O most probably do not have a moderate opinion: the presence of a MC in addition to a DK-O does not change the proportion of such respondents. However, they might have enough knowledge to form a positive or critical opinion regarding the question if they are forced to, since the respective share of other response categories does not statistically significantly change when a DK-O is present compared with when it is not—provided that those who choose the MC are not included in the analysis.
Conversely, respondents choosing a MC do not necessarily have a moderate view: the presence of a DK-O in addition to a MC does reduce the proportion of the latter. Moreover, the absence of a MC does change the share of other regular answer categories—then respondents would opt for a different regular answer category. Therefore, a systematic response pattern occurs, depending on the availability of a MC.
Based on this outcome, two consecutive steps for future projects can be advised. (1) Regarding the questionnaire design: Questions that trigger a lack of knowledge should be avoided — this is a known basic rule. Nonetheless, a DK-O should not be omitted in general, presuming that the proportion of inexperienced respondents is relatively high. Including a filter question before a question block dealing with a topic that requires previous experience could help avoid overtaxing these respondents. In contrast, offering or omitting a MC is a more difficult decision. If the group of respondents with a moderate opinion is very small, a MC can be used to identify respondents with a systematic response behavior. Either way, pretests should be conducted to determine the respondents’ reasons for choosing a MC. (2) Regarding the main survey: The sample composition should be determined as regard the participants’ knowledge on the topic (experienced, inexperienced, and moderate). The proportions of different types of survey participants should be specified and considered in the data analyses.
Finally, these results are an important step for the further investigation of scale-based responses. Subsequently, further investigation is required as to what extent random choices vs. systematic choices are made depending on the scale format and the respondents’ knowledge on the topic.
Limitations have to be considered. Data were collected by means of an online survey dealing with student participation at a university in Austria. Therefore, the results are not generalizable but form a starting point for further investigations. However, the results might be different, when another number of answer categories (e.g. six instead of four) is chosen. Moreover, the concept of the measuring scales seems to be optimizable. This will be followed up in a further research project.
Corresponding Author:
Daniela Wetzelhütter, University of Applied Sciences Upper Austria, Garnisonstraße 21, 4020 Linz, Austria
E-mail: daniela.wetzelhuetter@fh-linz.at, Phone number: 0043 50804-52430

