Psychometric scale development remains an important part of survey methodology and social science research; requiring item generation, factor analysis, and reliability assessment (e.g., Krumm et al. 2024; Stefana et al. 2025). This rigorous process often requires a level of expertise and training to ensure proper scale development. Recent advances in Artificial Intelligence (AI), particularly Large Language Models (LLMs) such as ChatGPT, may shift how scales are created, allowing individuals without methodological expertise to create scales that function comparably to conventionally developed scales (Beghetto et al. 2025; Götz et al. 2024).
AI in Item and Scale Generation with Human Oversight
Early work, such as the AI-IP project and the Psychometric Item Generator, display an ability to create large pools of related items that could then be reduced by expert intervention (Götz et al. 2024; Hernandez and Nie 2022). Such programs increase efficiency by reducing the time experts spend curating large numbers of verbally similar items but still require expert guidance for proper scale construction (Hernandez and Nie 2022; Wang and Chuang 2023). However, most AI-generated instruments required expert revision to ensure the generated language for each of the items adhere to the underlying construct without becoming redundant (Franco-Martínez et al. 2023; Laverghetta and Licato 2023; Mussel 2025). These programs highlight the underlying question of whether LLM AI tools can create psychometrically valid scales without the intervention or oversight of experts.
Toward Democratization of Scale Development
Beyond the importance of streamlining scale creation, it can be argued that AI represents a shift toward a methodological democratization where these tools support, but do not replace, expertise (Smith et al. 2025). Widespread adoption of increasingly competent tools like ChatGPT allows for the possibility that non-experts could design functional scales with little methodological training. This could democratize access to, and reduce the costs of, scale creation, for the purposes of applied research and surveys. This may be particularly prescient for arenas that utilize rapid, iterative approaches to research. However, this process is rife with concerns regarding the cultural bias of LLM tools, a point that may deeply impact the construction of scales designed to study rare or stigmatized facets of the human experience (Dong and Dumas 2025).
Current Study
The present study evaluates whether unedited, ChatGPT-generated scales are comparable to conventionally developed and well-established instruments. We set out to test these scales “as is” against established measures of self-esteem and right-wing authoritarianism. By focusing on factor structure, internal consistency, convergent validity, and Bland–Altman agreement, our work provides early guidance on whether LLMs can produce ready-to-use instruments without expert intervention. This work contributes to debates on the proper place, utilization, and abilities of LLM AI tools within the broader survey research space.
Method
Participants
A total of 140 undergraduates were recruited through the department’s Sona system at a medium-sized Mountain West university. Participants (76% female, 19% male, 5% non-binary) averaged 25.16 years of age (SD = 7.22). Race/ethnicity was reported as White/Caucasian (60%), Hispanic/Latino (40%), Black/African American (15%), Asian (13%), Native Hawaiian/Pacific Islander (6%), American Indian/Alaska Native (3%), and Other (20%).
Measures
AI-Generated Scales
GPT-4 Turbo was prompted to create a self-esteem scale (“create a scale for measuring self-esteem”) and a right-wing authoritarianism (RWA) scale (“construct a 15-item right-wing authoritarianism scale”. This work highlights short (≤ 15 items) because most non-experts are likely hunting for short scales that facilitate quicker survey completion. The self-esteem scale was indicated as unidimensional; the RWA scale included three proposed subscales: submission to authority, aggression toward outgroups, and conventionalism (OpenAI 2024). Items for both scales were rated from 1 (Strongly Disagree) to 5 (Strongly Agree).
Conventional Scales
For comparison, Rosenberg’s (1979) Self-Esteem Scale (RSES) was used, consisting of 10 items (five positively worded, five negatively worded) with a 1(Strongly Disagree) to 4 (Strongly Agree) response scale. For RWA, Altemeyer’s (2022) 10-item short form was used. Although originally designed and argued to be unidimensional, prior evidence strongly supports a three-factor structure (submission, aggression, conventionalism; Zakrisson 2005).
Analytic Approach
Principal components analyses were conducted on each conventional and AI-generated scale and subscale. Reliability was assessed with Cronbach’s α, with Feldt’s tests used to compare reliability between conventional and AI-generated scales. Convergent validity was examined using correlations and paired-samples t-tests. Agreement between the scales was assessed with Bland–Altman analyses.
Results
Initially, each scale was assessed for face validity (see Appendix for full item breakdown for both scales). Because LLMs are trained on text blocks that may include existing psychological scales, we explicitly examined the degree of overlap between the AI-generated items and the conventional comparison scales. Two authors independently compared each AI-generated item to items from the corresponding conventional scale and classified them as (a) verbatim or near-verbatim paraphrases, (b) conceptually similar but distinct in wording, or (c) novel content with no clear counterpart.
No AI-generated items were verbatim copies of existing items, and only two (2) of 25 items were judged to be close paraphrases. Those were Item 1 on the RSES and Item 2 on the AISES; Item 6 on RWA-10 and Item 3 on AIRWA. The majority of items were classified as conceptually similar but distinct. Additionally, there were two items in the AISES (Items 6 and 7) that had no correlates in the RSES, and three items in the RWA-10 (7, 8, and 10) that were judged to be conceptually distinct from any of the 15 items in the AIRWA scale. So, although the AI-generated scales were intentionally organized around the same conceptual domains and subdomains as the original RSES and RWA-10 scales to facilitate comparison, the specific item wordings are not simple reproductions of the existing measures within the RWA-10 or RSES.
When comparing the AI-generated scales to other existing scale items, item reproduction did exist. The AIRWA was compared to the items from four additional right-wing authoritarianism scales (Bizumic and Duckitt 2018; Funke 2005; Manganelli Rattazzi et al. 2007; Zakrisson 2005). The first item in the AIRWA scale appears to be nearly a verbatim copy of an item that appears in both the Funke (2005) and Manganelli Rattazzi et al. (2007) scales. Additionally, Item 1 appears in a very similar capacity in the American National Election Studies (ANES) childrearing battery. Although there are no other verbatim copies there are several items that are linguistically very similar to items that appear in one or more of the five conventional scales. The items in the AISES were then compared to two self-esteem scales (Helmreich and Stapp 1974; Ryden 1978) and the Ryff Psychological Well-Being Scale (1989). Though no item was a verbatim copy of existing items, Items 1, 3, 4, 6, 7, and 10 were semantically very similar to items in the existing conventional scales.
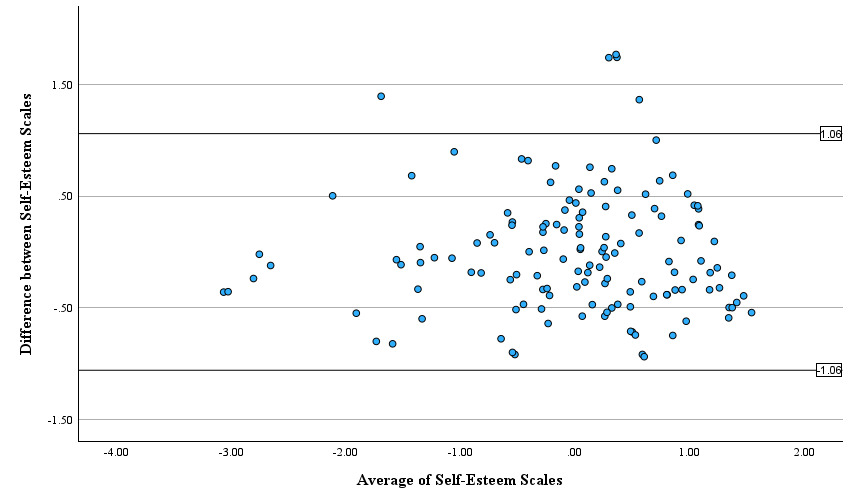
As shown in Table 1, both self-esteem scales explained a similar amount variance, though the AI version yielded higher internal consistency. The AI-generated scale resulted in a single-factor solution operating as described, and RSES resulted in the familiar two-factor solution along lines of positive/negative question wording. Both self-esteem scales correlated strongly, and paired samples t-tests revealed no mean differences between the standardized scales. Bland–Altman analysis indicated negligible bias and no proportional error, suggesting strong agreement between the conventional and AI-generated scales.[1]
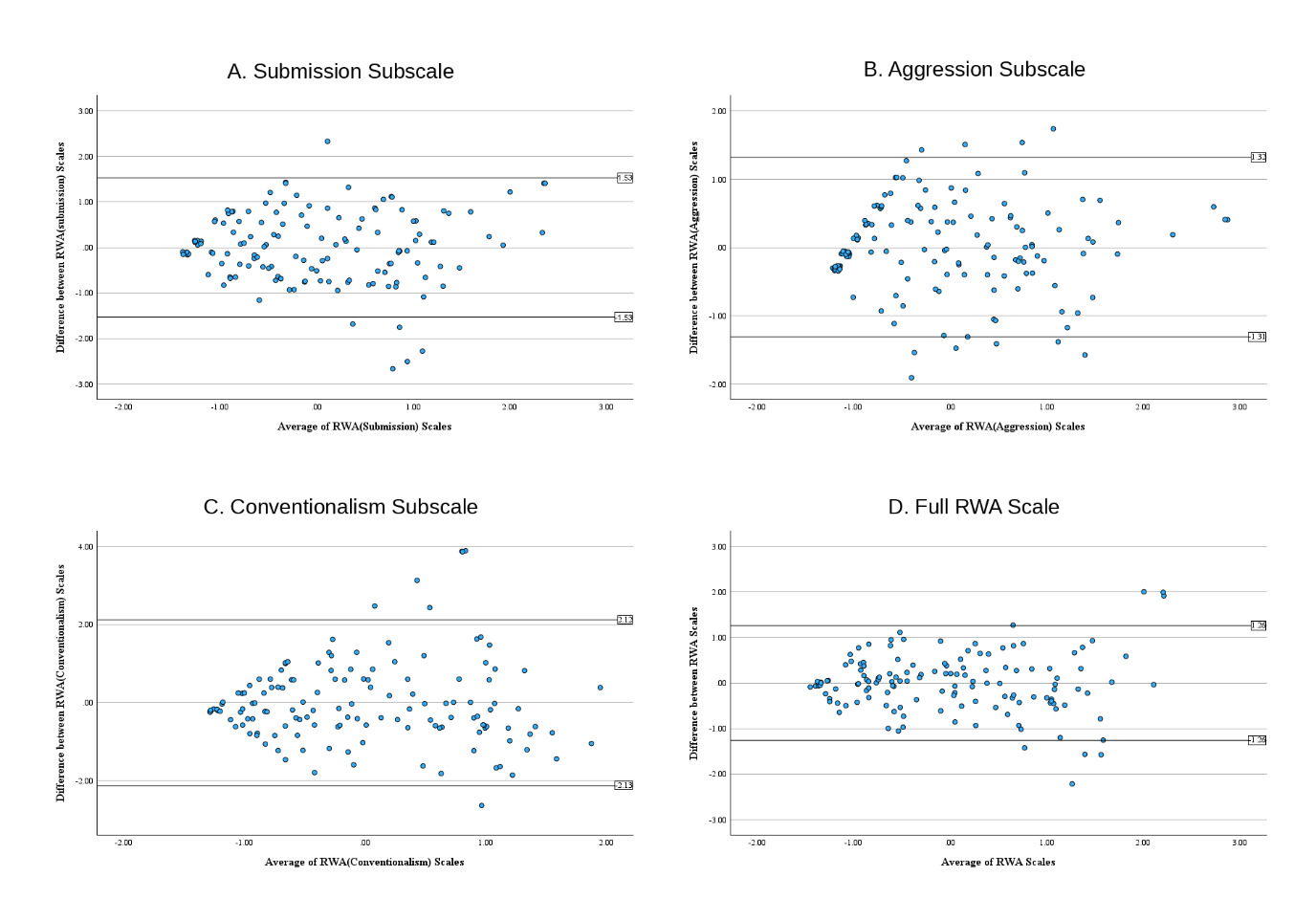
For RWA, Tables 2 and 3 show analyses for the three subscales identified in prior research and by ChatGPT, with correlations ranging from modest (conventionalism) to strong (submission, aggression). When both RWA scales were forced into a single-factor solution (Table 4), the AI scale demonstrated stronger internal consistency and remained highly correlated with the RWA-10, indicating comparable coverage of broader construct. Bland–Altman analyses revealed negligible bias at the full-scale level but wider limits of agreement for the subscales, suggesting greater individual variability in subscale scores (see Figures 1 and 2).


Discussion
This study assessed whether unedited AI-generated scales could perform comparably to established psychometric instruments. Across both self-esteem and right-wing authoritarianism, the AI-generated scales and subscales showed reliability, factor structures, and correlations similar to, or stronger than, those of the conventional scales and subscales. Bland–Altman analyses revealed negligible bias at the full-scale level, with no evidence of proportional error. Taken together, these findings suggest that, without expert refinement, AI-generated instruments may function as viable tools for research purposes.
However, our results also point to the potential limits for AI-generation. Importantly, we do not claim that the LLM AI is generating scale items ex nihilo; outputs are almost certainly informed by exposure to text that overlaps with existing measures. Our focus here is on whether LLMs can efficiently produce item pools that (a) avoid verbatim reuse of existing items and (b) reproduce the psychometric structure and performance of established scales, thereby offering a practical tool for adapting or extending measurement in new contexts. In this area there are admittedly mixed results. As indicated, ChatGPT 4-Turbo engaged in some verbatim or nearly semantically identical item construction. However, given the well-trodden area both scales address, combined with the issue of content validity and what Haynes et al. (1995) call the “universe of items” that could be reasonably created, true item novelty may be difficult for experts and AI alike.
Additionally, analyses of the subscales show wider limits of agreement, indicating greater variability at more refined levels of measurement. This highlights the continued importance of expert review, particularly when instruments are intended to capture complex, multidimensional constructs, or provide greater degrees of measurement precision. Although our work addressed reliability and agreement, we did not examine cultural bias, redundancy, or conceptual drift; concerns well-cited in prior research (Franco-Martínez et al. 2023; Mussel 2025). Nor does our work address perhaps the most fundamental issue with the use of LLM AI in this domain; the fact that the programmatic default for AI-generated scales is the development of new “jangles” (Kelley 1927) that gravitate toward linguistically newer but nearly identical versions of existing items within the nomological net of a construct.
Another limitation concerns scope and generalizability. Our study focused on two well-established measures for well-studied constructs (self-esteem and RWA) within a sample of undergraduates. Although these constructs offer strong test cases, broader replication across domains and populations is necessary. Additionally, survey practice contexts often require scales that function within defined time and budget constraints. AI-generated scales could provide a solution in such cases, but their use and viability should be tempered by individual project needs pertaining to precision and cultural bias.
Our limited work currently supports the democratizing potential of LLMs in psychometric scale development. These tools may lower the barriers to creating reliable ready-to-use instruments. AI-generated scales may increase access to the ability to create valid measurement tools for non-experts, practitioners, and researchers working under resource constraints. However, democratization should not be mistaken for full automation or novelty. Even if AI-generated instruments demonstrate strong psychometric properties in initial tests, expert oversight remains critical for ensuring conceptual clarity, cultural sensitivity, and alignment with established theory.
Future research should extend this work by testing additional constructs – particularly development of novel scales without current counterparts, purposeful creation of short-form scales, applying cross-cultural samples, and exploring real-world survey contexts where rapid scale development is needed. Ultimately, our findings provide cautious optimism: with limited vetting, AI-generated scales may serve as practical tools in many settings, marking a meaningful step toward more accessible, efficient, and inclusive measurement practices.
Implications for Practice
Findings from this study suggest that unedited AI-generated scales can perform comparably to established measures on key psychometric indices. For survey practitioners, this opens the possibility of rapidly generating instruments when time or resources are limited. Tools such as ChatGPT can help create scales that approximate conventional tools’ reliability and structure, reducing barriers to measurement in many applied settings and potentially democratizing the research process for organizations with limited analytic capacity.
At the same time, these tools should be used with caution. Wider variability at the subscale level, along with unresolved issues of cultural bias and conceptual drift, underscores the importance of expert review. As AI becomes more widely adopted—often without direct involvement from measurement specialists—it will be increasingly important to evaluate the quality of unedited, AI-generated scales, especially given the potential for significant linguistic similarity with existing scales. Practitioners may treat AI-generated items as an efficient starting point, but any resulting scale should be thoroughly vetted and, when necessary, revised before deployment. With responsible application, AI-based item generation can enhance accessibility, reduce costs, and meaningfully expand the toolkit of applied survey research.