
Introduction
Behavior coding is a pretesting method where standardized codes are assigned to behaviors that interviewers and respondents display during the question/response process (Fowler and Cannell 1996). The method can be used to evaluate and improve questionnaires by, for example, helping identify survey questions that are problematic and identify aspects of interviewer training that could be strengthened. Until relatively recently, the utility of behavior coding was somewhat limited by sheer mechanics. Interviews were recorded on cassette tapes using a device attached to the telephone (for computer-assisted telephone interviewing [CATI]) or with an external recorder (for computer-assisted personal interviewing [CAPI]). Both methods proved onerous and limited the number of cases and the range and diversity of characteristics of cases that could be recorded. In 1999, RTI and the Census Bureau collaborated on a project to assess the feasibility of computer audio recorded interviewing (CARI), a system capable of capturing digital recordings directly on to CAPI laptop computers (Biemer et al. 2000). In 2009, the system was adapted to include CATI recordings. The system also incorporated a software interface that allowed the coder to listen to the recording while viewing screen shots of the questions as displayed during the interview, and to enter behavior codes (including open-text notes).
This enhanced CARI system was first piloted in the 2010 American Community Survey (ACS) Content Test. The production ACS is first administered by mail; then a CATI interview is attempted for mail nonrespondents, followed by a CAPI interview with a portion of the CATI nonrespondents (Pascale et al. 2013). The 2010 content test mimicked this design, using experienced interviewers, and its purpose was to evaluate improvements to existing ACS questions and alternative versions of questions on new topic areas. The questions flagged for testing were inserted into the existing ACS questionnaire, and two versions of the instrument were developed – a test and a control. Behavior coding was one of several methods employed in the evaluation to aid the project sponsor in choosing between the test and control versions for production ACS. Nine topic areas and a total of 54 items were flagged for the behavior coding component of the evaluation. The main research question was whether the test or control version showed higher rates of standardized interviewer behavior and respondent behavior that was consistent with lower measurement error. (See Pascale et al. [2013], for a full report.)
The purpose of this paper is not to present the comprehensive set of results on the ACS Content Test per se, but to highlight some of the findings to demonstrate the advantages CARI brought to the behavior coding method. Many of these advantages were not necessarily unique to CARI, but the practical ease of recording (compared to traditional methods) dramatically increased the sheer volume of recordings that could be captured with minimal effort. This, in turn, greatly enriched the range of possibilities for analysis. Quotas of cases with specified characteristics – including relatively rare events such as receipt of public assistance – were identified a priori for recording. They were then coded in sufficient numbers to generate standard errors that could be used to evaluate test/control comparisons. Post-data collection, households and people with characteristics that emerged as being of interest for more in-depth analysis were identified for targeted behavior coding analysis. The topic areas of Food Stamps, public assistance and parental place of birth are highlighted below to illustrate these advantages.
There were also advantages unique to CARI. In terms of operations, research staff was able to listen to recordings while data collection was ongoing in order to develop tailored behavior codes before the survey was out of the field. Staff was also able to monitor coding operations in real time for quality assurance purposes and to conduct retraining as needed. And, because coders could see a screen shot of the instrument and hear both interviewer and respondent audio at the same time, the coder could evaluate whether the interviewer correctly keyed in the respondent’s answer.
Methods
The field period for the ACS Content Test was late August through mid-December 2010, with CATI cases followed by CAPI cases, and interviews in English and Spanish were conducted in each mode. To ensure an adequate number of recordings of each topic area without overtaxing the digital storage and transmission capacity, a quota of recordings was set for each topic area rather than recording the interviews in full. Interviews, or designated subsets of interviews, were recorded and coded for a total of 1,427 households. Of these, 77 percent (1,092) were conducted in English and the remainder in Spanish, and 51 percent were CATI and 49 percent CAPI. Eight bilingual telephone interviewers from the Tucson Telephone Center served as coders and were trained by staff from the Center for Survey Measurement (CSM). Training was held December 7–10, 2010, and coding operations were conducted from December 13, 2010, through March 6, 2011. Behavior coding data were then cleaned and processed by CSM staff.
For this study, the unit of analysis was a “turn” of speech for either interviewer or respondent. A turn begins when one person starts speaking and ends when the other person starts speaking. The starting point for development of the codes was a fairly standard set of behavior codes, which was adapted based on the analysis goals and by listening to recordings from the field. A measure of inter-rater reliability was calculated by assigning a subset of eight cases to all eight coders and then using the kappa statistic to measure the agreement across coders. According to Fleiss (1981), kappa scores can be categorized as follows: higher than 0.75 represent an excellent level of agreement, 0.40 to 0.75 represent a “good” to “fair” level of agreement, and scores below 0.40 indicate poor agreement. Overall, the kappa score for interviewer behavior codes was 0.502, and for respondent codes, the score was 0.463. One factor contributing to the relatively low reliability was that the recordings were sometimes out of sync with the item name and screen shot. To reduce file size and transmission time in the pilot, rather than make a continuous recording for a given case or topic area, recordings were made at the question-level. The recorder switched on when the interviewer entered an item screen and turned off when the interviewer moved off that screen. In many instances, this was problematic because interviewers moved on to the next screen before waiting for the answer, so the respondent’s full response was cut off.
Results
Interviewer First-level behavior
Across all 54 items targeted for behavior coding, there were 20,352 administrations of questions, for an average of 377 administrations per question. See Table 1 for summary results of interviewer first-level behavior codes for a subset of items. “Standardized” behavior indicates that the interviewer read the question as worded (or with a slight change) or correctly verified the question. Note that for some topic areas (e.g., computer devices), there is a test version of the question and a corresponding control version; the only difference was in placement in the questionnaire. For other topic areas (e.g., property income), there is not a one-to-one match of items, but a whole control series vs a whole test series. For the most part, for topic areas where a whole series of different questions was changed, the test version decomposed or clarified the original control question into simpler component parts.
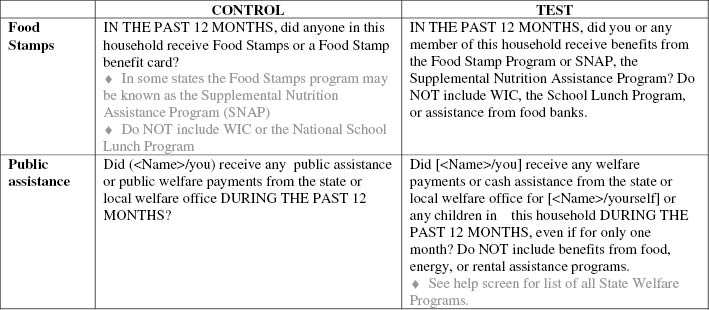
Results show that overall, interviewers displayed standardized behavior 45 percent of the time, with no difference between test and control items as a whole. However, there was wide variation across topic areas and items. There were few test-control differences among items where the wording was the same across versions, as in the internet subscription type, computer device and parental place of birth items. For most of the topic areas where the test version was a decomposition of complex questions (property income, wages, veterans status/military service), rates of interviewer standardized behavior were higher in the test than the control version. For both Food Stamps and public assistance, there were large and significant differences – 73 vs 34 percent (control/test) and 44 vs 22 percent (control/test), respectively.
The test versions of both the Food Stamps and public assistance items were modified in an attempt to reduce underreporting. For Food Stamps, the program name had recently been changed to the Supplemental Nutrition Assistance Program (SNAP). The control version displayed this new program name in an optional interviewer instruction, while the test item embedded the new program name in the question itself (see Figure 1). The open-text notes on nonstandardized readings were categorized and quantified (see Table 2). Results show that in the control, 73 percent (row 1) read the question verbatim and that interviewers, as per instructions, never read the new SNAP program name from the optional text in the initial administration of the question. In the test version, only 34 percent read the question verbatim, but an additional 32 percent provided both the old and new program names (adding rows 2, 3, and 13), though they modified other parts of the question. Thus, in total, in 66 percent of the test cases, respondents were provided with the “Food Stamps” and “SNAP” stimuli, compared to no respondents receiving the SNAP stimuli in the control version. However, in the remainder of the test cases, both SNAP and “Supplemental Nutrition Assistance Program” were dropped – meaning that respondents did not receive any version of the new program name in these cases.

Unlike in Food Stamps, where the actual name of the program had changed, the test version of the public assistance item was modified to highlight certain aspects of the program that were suspected to be driving some of the underreporting: receipt on behalf of children and participation for as little as one month (see Figure 1). Verbatim question-reading was 44 percent in the control and 22 percent in the test version. The most frequent type of change in the test version (24 percent of all administrations) was to stop reading after “…welfare office,” meaning the question essentially reverted to the control version and included neither phrase intended to reduce underreporting. However, in 14 percent of test cases, interviewers made mention of the key changes (children and “at least one month”) and another 11 percent mentioned children, even though they modified other parts of the question.
The wording of the parental place of birth items was identical in test and control, as was the sequence (father then mother); the only difference was placement within the larger instrument. Both questions were asked at the person-level about all household members (see Figure 2). The overall level of standardized behavior for these items was very low – 10–14 percent (see Table 1). In many households, the answer was the same for father and mother (that is, they were both born in the same country), and the answers were the same for all household members because they were all related. To investigate whether interviewers were reading the first administration of the question as worded and then abbreviating or skipping the question as they moved from one person to the next in the household, interviewer behavior by person number was examined. Table 3 shows a number of interesting results. For example, though the rate of exact readings did not drop as person number went up in a strictly linear pattern, there was a drop-off in exact readings after person 1. Furthermore, the overall rate of skips was 3 percent for the paternal version of the question but 14 percent for the maternal version.

Comparisons by Mode and Language
Overall, the rate of standardized interviewer behavior was seven percentage points higher in CATI than in CAPI (see Table 4). The rate of major change was about the same across modes, but in CAPI, the rate of skips was 9 percent vs 3 percent in CATI, and the rate of incorrect verifications was also somewhat higher in CAPI than in CATI (five vs three percent). There were also differences by language; standardized interviewer behavior in English was 54 percent overall, vs 37 percent in Spanish.
Summary and Discussion
Table 1 suggests that decomposing complex questions into simpler parts results in interviewers reading the questions as worded more often than when several concepts are grouped together into one question. An examination of the nature of wording changes to both the Food Stamps and public assistance items indicates that interviewers did strive to deliver the key stimuli of the test question that was new/different, even if they did not read the question in its entirety. These kinds of results could be leveraged by linking to actual survey frequencies. For example, the Food Stamps items could be grouped into three categories: those where the question was read exactly as worded, those that were not read as worded but where the key stimuli (at least “Food Stamps” and “SNAP”) were delivered, and those where neither key stimuli was delivered. Frequency of positive reports of Food Stamps would shed light on the implications of these changes.
Results from the parental place of birth questions suggest moving to a topic-based or household-based style of questioning for items where the answer is likely to be the same for all or most household members.
Results on mode are consistent with expectations. CATI interviewers are regularly monitored by their supervisors in a centralized facility. CAPI interviewers are not as accustomed to regular monitoring and feedback, which could explain their higher rates of skipping and incorrectly verifying questions. The CARI system has the potential to “even the playing field” between CATI and CAPI and introduce CAPI interviewers to more frequent monitoring and more coaching from supervisory staff.
Many of the analyses conducted in this pilot are not unique to CARI; they are certainly possible using conventional behavior coding methods. However, CARI made it much more feasible to target specific topic areas and individual items to be recorded beforehand, and to flag specific characteristics of the interview after-the-fact for more in-depth analysis. Furthermore, this pilot only went as far as evaluating the interviewer-respondent interaction. The results could be leveraged for much more value by linking to the actual survey frequencies and conducting further analysis on the associations between characteristics of the interaction and the final survey estimates.
Due to unexpected technical difficulties, 20 percent of respondent first-level turns were coded as inaudible and most of these were driven by CAPI cases, which had an inaudible rate of 37 percent. This compromised the analysis of respondent behavior, as well as the data entry match. Overall, only one percent of cases were coded as a mismatch (that is, the answer keyed in by the interviewer did not match that provided by the respondent) and 75 percent were coded as a match. The remaining 24 percent of cases were “undetermined,” and among these, the respondent’s final answer was coded inaudible 83 percent of the time. Future use of CARI to evaluate CAPI interviews should include a pilot field test for audio quality of CAPI recordings. It is also recommended to record a continuous segment of an interview rather than at the question level.