

There are several reasons to consider mixed-mode data collection procedures in survey sampling. De Leeuw (2005) emphasized that mixing modes of data collection can improve data quality and response rates, since the disadvantages of one mode can be compensated with the advantages of other modes. A second driving force behind mixed-mode designs is the reduction of administration costs of a survey. Cost is an important limiting factor in survey research and is the main reason that the Dutch Integrated Safety Monitor (ISM) employs a sequential mixed-mode strategy using web interviewing (WI), paper and pencil interviewing (PAPI), computer assisted telephone interviewing (CATI) and computer assisted personal interviewing (CAPI). While CAPI is the most costly mode, it is applied in the ISM to reach subpopulations traditionally known to be difficult to contact through the other modes. The ISM has now been conducted twice. In this paper the importance of including CAPI is assessed. It is investigated how sensitive the representativity of the response and the survey outcomes are to omission of the CAPI mode.
Survey design
The purpose of the ISM is to publish figures about justice and crime victimisation, police performance, and security perception of the Dutch population aged 15 years and over. In its present form, this survey has been conducted in the fourth quarter of 2008 and 2009. A stratified sample of persons is drawn using the 25 police districts in the Netherlands as stratum variable.
The data collection of the ISM follows a sequential mixed-mode design. All sampled persons are approached for WI with an advance letter inviting them to complete a questionnaire on the website of Statistics Netherlands. Alternatively respondents can receive a PAPI-questionnaire on their request. Persons with a listed landline or mobile telephone number who did not respond after two reminders are approached by telephone by an interviewer (CATI). The remaining persons who did not respond after two reminders are visited by an interviewer at home (CAPI). Table 1 shows the sample size, response rate, and the proportion of the response collected through CAPI. While the 2008 sample is smaller than the 2009 sample, the response rate is close to 60 percent in both years, with a proportion collected through CAPI of just over 10 percent.
The weighting procedure of the ISM is based on linear weighting. This implies that estimates of population parameters are obtained from functions of the observations in the sample expanded with the so-called survey weights. The generalised regression (GREG) estimator is used to derive the survey weights from the sampling design and the available auxiliary information about the target population (Särndal, Swensson, and Wretman 1992). The weighting model includes age, gender, ethnicity, household size, urbanisation and police district.
Assessing the effect of personal interviewing
While CAPI is the most expensive mode, it was believed that this mode is necessary to obtain a sufficient representation in the sample of groups that are known to be difficult to reach, such as young people and immigrants. Since the ISM has been conducted twice, the necessity of the CAPI mode can be studied in a relatively straightforward manner. The representativity of the response obtained with WI, PAPI and CATI and the additional value of CAPI is analysed in the next section with respect to some auxiliary variables for which the true population distributions are known. Subsequently the effect of the CAPI mode on the outcomes of the ISM is analysed by comparing estimates based on the complete sample with estimates based on the sample with the CAPI response omitted.
Characterisation of CAPI respondents
Mode dependent selection effects can cause the sample units who responded through CAPI to differ from those who responded through the other modes. To charactarise the CAPI respondents a weighted logistic regression model is fitted, with the weights those obtained through GREG estimation. By including these survey weights, selectivity with respect to the variables included in the weighting model is removed prior to studying their correlation with response mode. The dependent variable is a binary indicator for responding through CAPI.
In a first model, the independent variables are the same as those used in the weighting model, without interactions. The regression coefficient of gender is not significantly different from zero, see Table 2. The remaining variables are significant, police district having a larger p-value than the others. Two more models are fitted (see Table 2). Gender and police district are left out, but interaction terms with urbanisation and household size are now included. The only interaction that is not significant is that of urbanisation and ethnicity. While Table 2 is based on 2009 data, similar results are obtained for 2008. These findings imply that CAPI is a data collection mode suited to reach particular subpopulations with respect to age, ethnicity, household size and urbanisation.
Comparing the distributions of these variables in the CAPI group and in the non-CAPI group, CAPI is found to be successful in reaching young people, non-western immigrants, small households, and people living in urban areas. As an example, the distribution of age in the 2009 sample is shown in Figure 1. The pattern that emerges is due to selection effects only, as oversampling of specific demographic strata is not part of the sampling design. Among the CAPI respondents, the age groups of up to the age of 39 are overrepresented, while older respondents are underrepresented. For the non-CAPI group the reverse is true, though the deviation from the distribution in the population is not as severe. The distribution in the complete sample is the same as that in the population, since the sample is weighted by age.

If the CAPI respondents are omitted from the sample, the remaining response will have an underrepresentation of the younger age groups. Similar arguments apply to ethnicity, houshold size and urbanisation, and show that CAPI is a mode particularly suited to reach non-western immigrants, small families, and people living in cities.
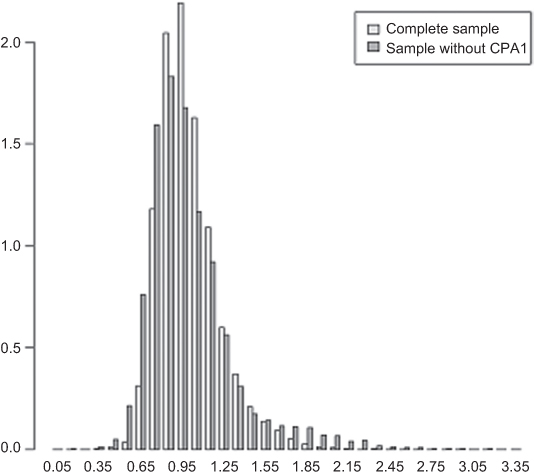
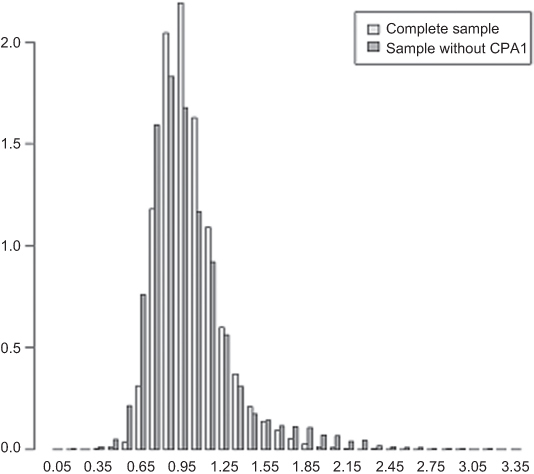
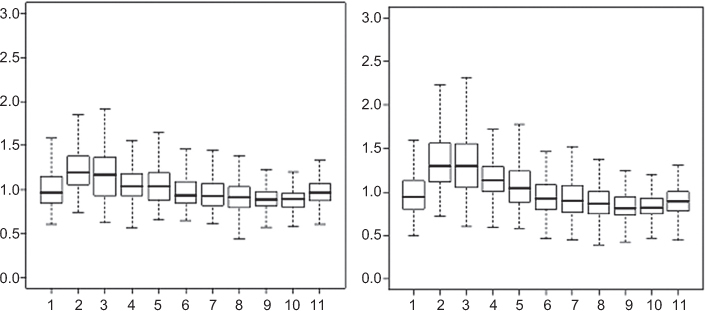
Applying the GREG weighting model used for the complete sample to the sample excluding the CAPI response results in a new set of weights. Figure 2 shows these new weights together with the weights of the complete sample, for the ISM data of 2009. As expected the distribution of weights for the sample without CAPI respondents has a larger tail to the right, indicating that the sample is less representative. Figure 3 presents the distribution of weights by age group. In the sample without CAPI, the weights of the younger age groups are larger and more widely spread than those of the complete sample, while the differences in weights are smaller for the older age groups. This confirms that omitting CAPI respondents has an adverse effect on the representation of younger people. Similarly, the representation of non-western immigrants, small households, and people from urban areas is worse in the sample without CAPI than it is in the complete sample.
Survey outcomes
Some statistical outcomes of the ISM are shown in Table 3. This table contains estimates for eight key variables, for 2008 and 2009, calculated using the complete sample and the sample without CAPI. There is little difference between the point estimates based on the two samples. Ordinary tests for significance of the observed differences cannot be applied since the samples are not independent, due to the sample overlap. The point estimates based on the sample without CAPI are mostly within two standard errors of the estimates based on the full sample. There are three variables in 2009 for which this is not the case, as indicated in Table 3. This does not occur in 2008. These differences are caused by selection effects and mode effects, which are strongly confounded. Jäckle, Roberts, and Lynn (2010) discuss the issue of comparability of microdata collected using different modes.
The standard errors of the estimates based on the sample excluding CAPI are larger than those based on the complete sample. The reason for this is twofold: there is more variation between the weights, as shown before, and the sample size becomes smaller when omitting part of the response.
Table 4 shows the annual mutation in the estimates of the eight survey variables. While there are some differences between estimates based on the sample including CAPI and that without CAPI, there are no survey variables for which the two versions report conflicting developments.
Conclusions
The CAPI data collection mode is important to reach certain subpopulations that are otherwise underrepresented in the response. In particular, including CAPI is beneficial for the representation of young people, non-western immigrants, and people living in urban areas. Not conducting CAPI interviews causes the ISM response to be less representative, resulting in more extreme survey weights. Generally, this will have a negative effect on the variance estimates of the survey variables. Some of the eight survey variables considered are estimated differently based on the sample without CAPI compared to the complete sample, although in most cases there is no significant difference. The substantial reduction in survey cost that can be achieved by omitting the CAPI mode would come at the expense of a decrease in accuracy