

1. INTRODUCTION
Household probability surveys are useful for monitoring self-reported behaviors and beliefs over time.
As telephone random digit dialing (RDD) surveys suffer from continued and increasingly low response rates (Pierannunzi et al. 2019; Link et al. 2008); increasing costs associated with each interview (Guterbock et al. 2011); and increased field time needed to complete RDD surveys (Guterbock et al. 2011), researchers conducting RDD surveys have been experimenting with different strategies to improve survey participation and quality. One strategy that has been employed by many U.S. federal and state government sponsored health focused surveys is to transition RDD phone surveys to address-based mail or mixed-mode (mail and web) surveys. Some of these include the following: the Health Information National Trends Survey (HINTS; Finney Rutten et al. 2012; Peytchev, Ridenhour, and Krotki 2010), Behavioral Risk Factor Surveillance System (BRFSS) (Link et al. 2006) and the California Health Interview Survey (CHIS; Wells 2020).
While transitioning survey modes have become relatively common in the past two decades, significant care must be taken to understand the potential shifts in biases which may occur because of the change of mode of administration and to determine if survey trends can be accurately reported. The two main sources of potential bias when transitioning RDD to address-based sampling (ABS) are (1) sampling bias, resulting from differences in the makeup of the survey samples and differences in unit (sampled person) non-response between the two modes (RDD vs. ABS) and (2) measurement bias, resulting from the use of different data collection modes: phone interviews (RDD), online responses (ABS-web), and pencil and paper responses (ABS-paper).
This paper systematically examines each form of potential survey bias (see Table 1 for list of biases examined) and serves as a guide to survey researchers, seeking to transition survey modes, using a U.S. Food and Drug Administration (FDA) household probability survey to structure the discussion. We begin with a comparison of sampling bias due to sample composition differences and respondent non-response (section 3.1). We then assess measurement bias by testing for mode measurement equivalence (section 3.2); straightlining (section 3.3); and finally, social desirability and acquiescence (section 3.4). By comprehensively examining biases, researchers can make conclusions about the overall success of the survey transition while also pinpointing specific questions that may require additional work before making trends comparisons.
2. DATA
2.1. Survey populations and sampling methods
Since the 1980s, the FDA regularly conducted national probability, cross-sectional, RDD interviewer-administered surveys to track consumer knowledge, exposure to and understanding of key food safety and nutrition messages, and related reported behaviors. In 2019, the FDA combined questions from the previous surveys and administered the FDA Food Safety and Nutrition Survey (FSANS) as an ABS, self-administered web and paper (paper and pencil) survey.
To assess the effects of the changes in survey administration mode, undistorted by temporal effects, the 2019 FSANS used a mixed-mode, parallel design, with participants assigned to ABS or RDD. This mixed-mode, parallel design provided an opportunity for mode measurement bias testing that few studies offer (Couper 2011).
Questions about food safety, health, and diet were included in the 2019 FSANS. There were two versions for each survey mode—one that focused on food safety and one that focused on nutrition. Two versions were needed to be able to include all questions of interest without burdening respondents with very long survey questionnaires. The RDD and ABS mode were designed to take 15 minutes and 20 minutes, respectively, to complete. The respondents for all versions of the survey were English- or Spanish-speaking non-institutionalized adults (≥18 years old) living in the 50 U.S. states and the District of Columbia.
Prior to conducting the survey, three rounds of cognitive interviews and a pretest were conducted to enhance survey understandability, minimize respondent fatigue, and ensure data integrity (completeness).
For details regarding the RDD and ABS sampling methods please refer to the Supplemental Material (S.1). The RDD data were collected from October 14, 2019, through December 22, 2019, and yielded a sample of 834 respondents, 415 of which were randomly assigned the Food Safety (FS) version, and 419 of which were assigned the Nutrition (N) version. The ABS data were collected from October 1, 2019, through November 2, 2019, and yielded a sample of 4,398 respondents, 2,227 of which were randomly assigned the FS version, and 2,171 of which were assigned the N version.
Survey data were weighted to account for sampling design and non-response. The sampling weights were calculated, separately for the RDD and ABS samples, to control for differential probabilities of selection (within household and across socio-demographic group).
The survey questions can be found in the 2019 FSANS report at https://www.fda.gov/food/science-research-food/2019-food-safety-and-nutrition-survey-report.
3. METHODS and RESULTS
In this section, we present the methods used to assess sampling bias and the results of each. We then present the methods used to assess mode measurement biases (each adjusted for any sampling bias found) and their results. Table 1 summarizes the methods used. Throughout this discussion, unless stated otherwise, data are weighted (i.e., sampling weights have been applied), and unless stated otherwise, all statistical analyses were performed using SAS 9.4 (SAS Institute, Cary, NC) and variances were estimated using Taylor series linearization (TSL). TSL is a method often used for computing the variance of a complex sample by reducing the form of a point estimate to a linear form by applying Taylor approximation and then uses the variance estimate for this linear approximation to estimate the variance of the point estimate (Woodruff 1971).
3.1. Sampling Bias: Sample Composition and Unit Non-response
3.1.1 Sample Composition—Methods Bivariate logistic regression, unweighted and weighted, was used to test for differential sample composition across mode. Since the ABS-web and ABS-paper were from the same sampling frame, the RDD sample was compared to the combined ABS-web and ABS-paper sample. Mode was regressed on each respondent characteristic: age, race and Hispanic origin, education, gender, income, urbanicity, region and home ownership.
Results: The differences in sample composition are presented in Table 4. Applying the survey sampling weights, successfully corrects for the mode sampling bias for all covariates adjusted for in the weight calibration process—i.e., gender, age, race and Hispanic origin, education, census region and urbanicity. Regarding the respondent characteristics not accounted for in the weight calibration process, income and home ownership, the combined weighted ABS-web/paper sample consisted of more homeowners and more high-income respondents than the weighted RDD sample.
3.1.2 Unit Non-response– Methods Non-response bias arises when survey respondents have different characteristics than the non-respondents, and those characteristics are correlated with survey estimates. Although, by definition, survey responses are unknown for non-respondents and thus non-response bias cannot directly be assessed, respondent characteristics of RDD and ABS (web/paper combined) were compared to the general U.S. population characteristics, as reported by the 2014-2018 American Community Survey (ACS; United States Census Bureau, n.d.), to ascertain potential non-response bias. Response rates in this paper were calculated using the American Association of Public Opinion Research (AAPOR) Response Rate 3 (RR3) formulation.
Results: The RDD RR3 was 6.6% and the ABS RR3 was 28.1%. There were indications of non-response bias related to age, education, gender, and race/ethnicity for both RDD and ABS (information available upon request). Notably, the RDD respondents trended slightly more male than the U.S. population, while ABS respondents trended more female than the U.S. population. Raking of the sampling weights to the ACS demographic control totals was performed to reduce these observed non-response biases in RDD and ABS.
3.2. Mode Measurement Equivalence
Methods The three modes (RDD, ABS-web, and ABS-paper) were assessed for measurement equivalence (ME). ME (also known as measurement invariance) is defined as ‘‘whether or not, under different conditions of observing and studying phenomena, measurement operations yield measures of the same attribute’’ (Horn and McArdle 1992). ME was assessed using multiple group confirmatory factor analysis (MGCFA) through a series of increasingly stringent models (Table 2), i.e., increasing number of constraints (Martinez-Gomez, Marin-Garcia, and Giraldo O’Meara 2017): (1) configural invariance; (2) metric invariance; (3) partial scalar invariance; (4) strict scalar invariance (Hox, De Leeuw, and Zijlmans 2015); and (5) latent factor variance invariance.
Model fits are generally considered good when the Root Mean Square Error of Approximation is low (RMSEA <.08) and the Comparative Fit Index is high (CFI >.90) (Van de Schoot et al., 2012). Further information about the model fit criteria can be found in the Supplemental material (S.2.1). As Barrett (2007) suggests, we calculated confidence intervals around the fit indices to parallel the logic of statistical inference of the chi-square test.
The five models are tested in sequence, looking for fit non-decreases (i.e., non-worsening) in chi square using the Satorra-Bentler scaled chi-square difference test (SBSD) (Satorra and Bentlee 2001). A non-significant SBSD test accompanied by a drop in CFI of at most .01 and an increase in RMSEA of at most .015 (Chen 2007) indicates the additional constraint will not cause a significant decrease in model fit. The model constraint can then be retained and the level of invariance to which the model corresponds is supported. Otherwise, that level of invariance is not established.
To avoid confounding sample compositional differences with mode measurement bias, the observed survey questions in the ME models were adjusted for mode selection effects using multiple propensity scores (Spreeuwenberg et al. 2010); i.e., adjusted for sampling bias. A discussion of the propensity scores can be found in the Supplemental material (S.2.2).
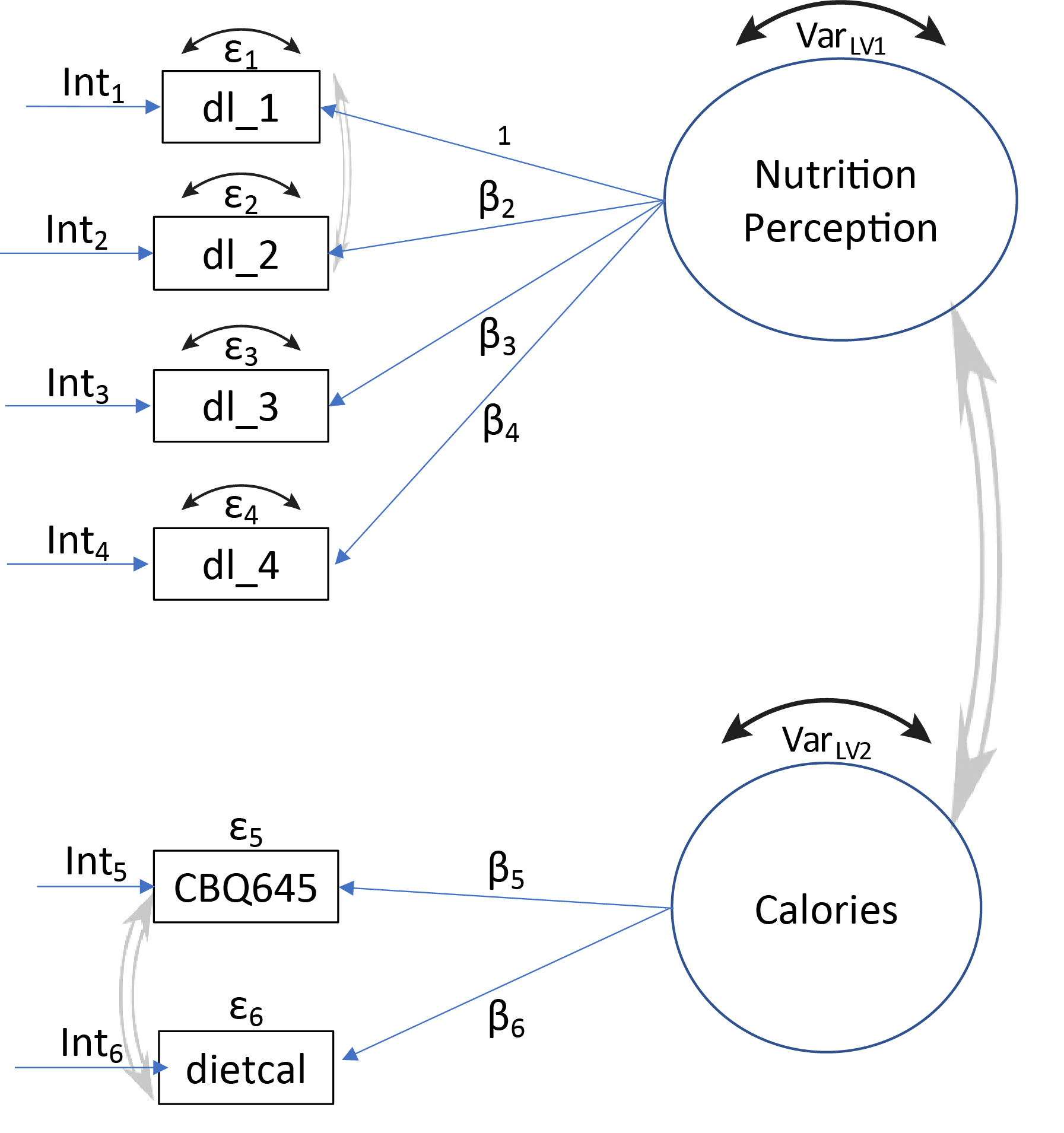
The manifest survey questions, measured on an ordinal or Likert-type scale, comprising the latent variables for each ME model, Food Safety Perception, Nutrition Awareness, and Food Handling Behavior are presented in Table 3. Figures 1, 2, and 3 illustrate the theoretical constructs of the three ME models. Most latent variables are represented by at least three survey questions. Further details regarding the inclusion of survey questions are in the Supplemental Material (S.2.3).
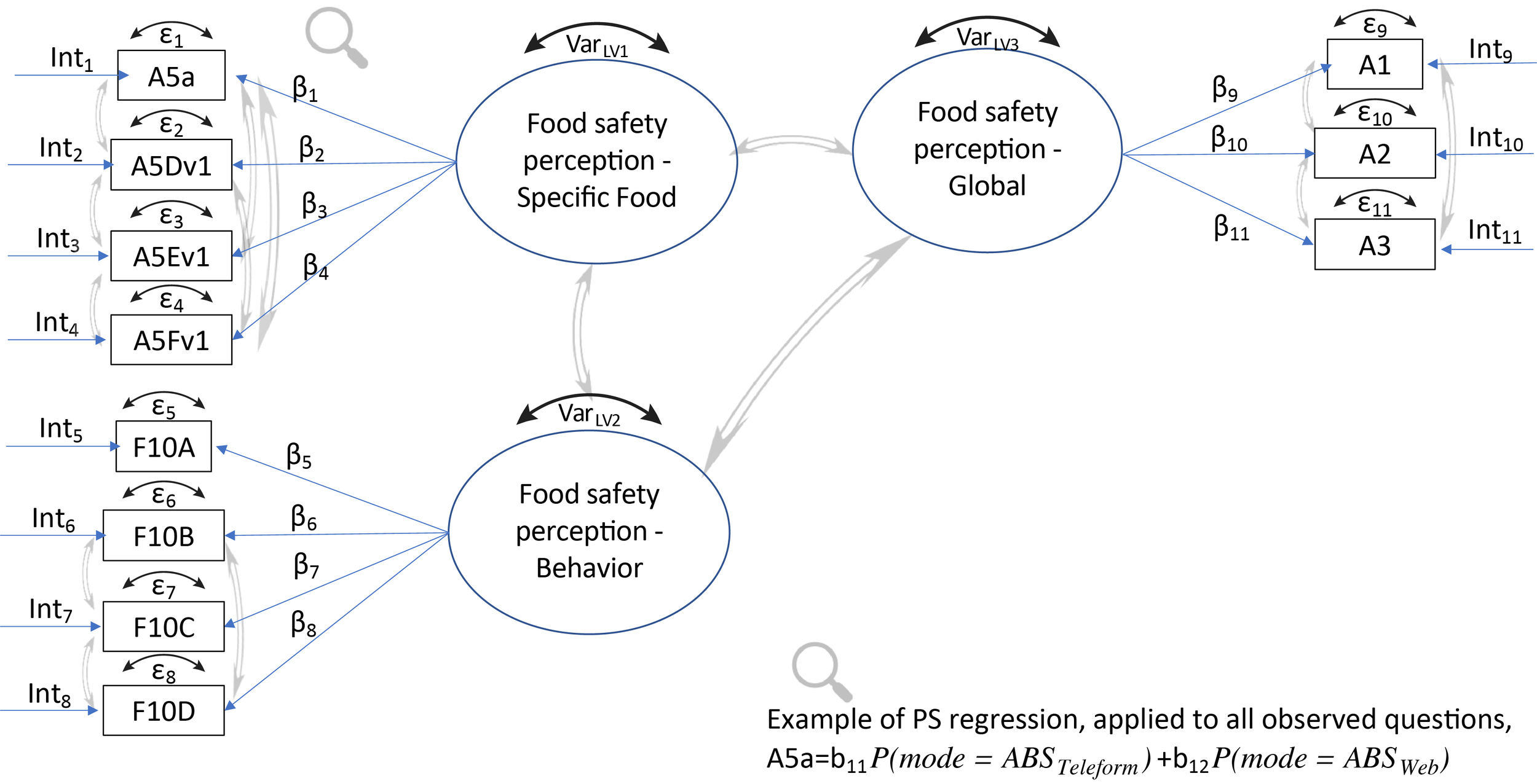
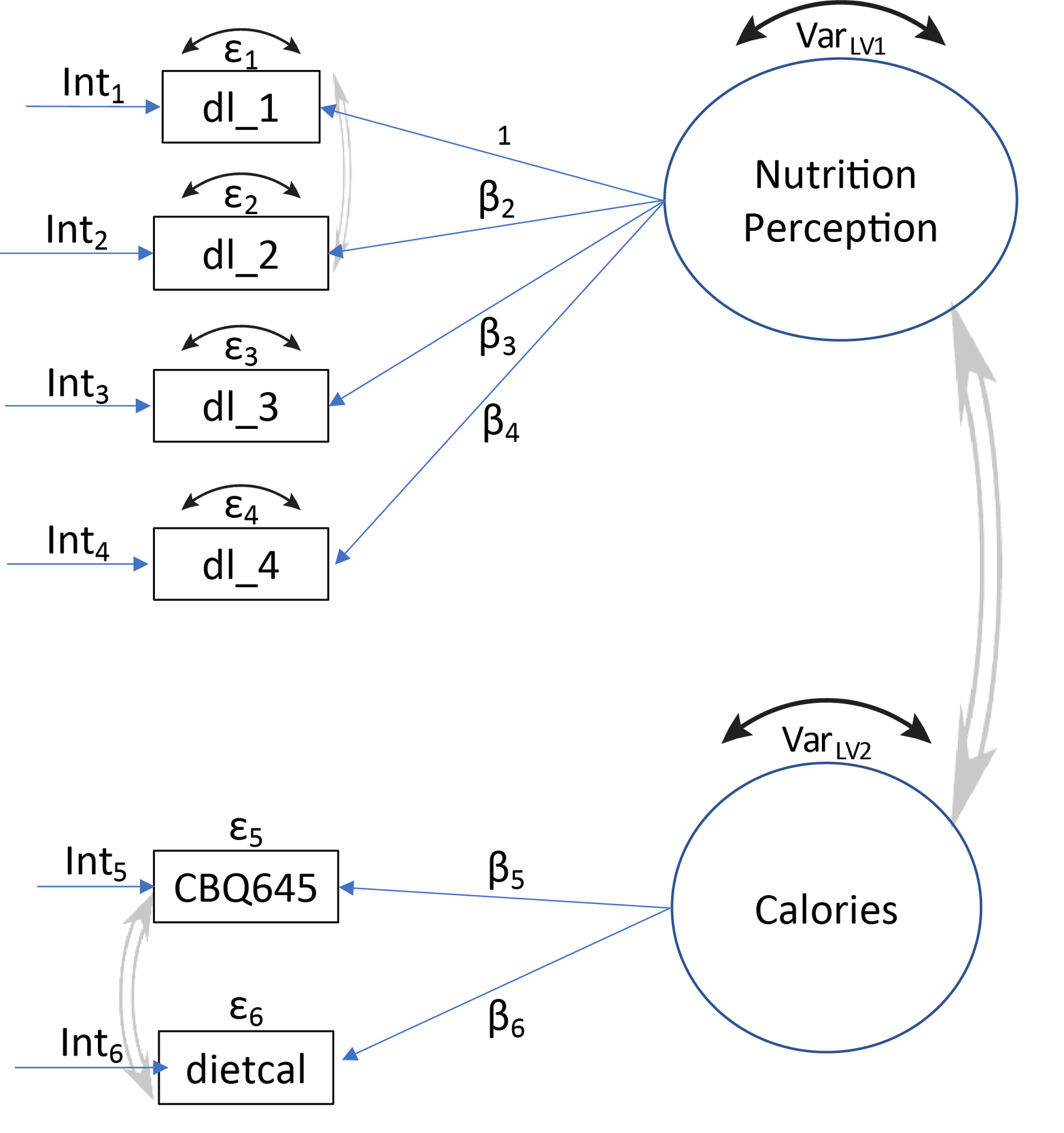

MGCFA was implemented using the cfa function in the R lavaan package (Rosseel 2012). Only complete cases (i.e., Blank/Refused excluded) were included in the ME models. Yoon and Lai (2018) indicate that the power to detect a violation of invariance decreases as the ratio of the mode sample sizes increases. The ABS web survey had 1,374 food safety and 1,393 nutrition cases; the ABS paper had 853 food safety cases and 778 nutrition cases; and the RDD survey had 415 food safety and 419 nutrition cases. To overcome this unbalance, a subsampling procedure was employed. One hundred bootstrap samples of size 415 for the Food Safety Perception and Food Handling Behavior ME models and 419 for the Nutrition ME model were randomly chosen from the ABS-web and ABS-paper data frames and the measurement equivalence analysis was run using each of these 100 subsamples and the full RDD sample (Yoon and Lai 2018). Measures of fit (CFI, RMSEA) were calculated for each of the 100 runs and their means and percentile-based 95% confidence intervals (2.5th percentile, 97.5th percentile) were then calculated across the 100 runs. The 100 SBSD test p-values were adjusted for multiplicity using the Bonferroni adjustment and the p.adjust function in the R stats package (R Core Team 2019), and the percentage of non-significant p-values (pBonferroni>.05) was calculated.
Results: Latent factor variance invariance, the highest form of mode equivalence, was established for the Food Safety and Food Handling models, and partial scalar invariance, the third highest form of mode equivalence, was established for the Nutrition model (Table 5a). The inability to establish strict scaler equivalence for the Nutrition model, suggests difference(s) in variances (precision) of the manifest variables across mode. Table 5b presents the coefficients of variation for the questions comprising the Nutrition model. In general, ABS-paper, and to a lesser extent ABS-web, had higher coefficients of variation than RDD.
3.3. Straightlining
Methods “Respondents who take “mental shortcuts,” are said to “satisfice,” by which it is meant that they do not (properly) perform all the necessary cognitive steps to answer a survey question” (Heerwegh and Loosveldt 2011). As shown in Table 1, one indicator of satisficing associated with speeding through grid or matrix questions on a self-administered survey is straightlining (Zhang and Conrad 2014). Low within-respondent variability may be a measure of low data quality in the form of straightlining and can be used to assess how attentively a respondent answered the survey (Cernat and Revilla 2020). Straightlining was assessed via the Standard Deviation of Battery Method (SDBM) (Kim et al. 2019). SDBM was calculated for each respondent by “battery group,” which are groups of related or connected questions, such as matrix or grid questions (Table 3). Linear regression was performed to assess the effect of mode on SDBM, while adjusting for covariates gender, race, age, education, income and urbanicity and adjusted means were compared across mode using two-tailed t-tests, for each battery group. Ninety-five percent confidence intervals were also calculated around the adjusted SDBM means assuming normality.
SDBMg=αg+βgX+εwhere g is the battery group, g=1,2,...7
Results: ABS-web and ABS-paper respondents had a greater tendency to straightline (i.e., lower SDBM) than RDD respondents for battery group 6 only (pweb =.0007, ppaper =.0006) (Table 6). This can most likely be explained by the way the questions were presented. The RDD survey posed each question in battery 6, “Have you heard of…,” individually for each pathogen, whereas the ABS survey posed one mark-all-that-apply question with a check box for each pathogen.
3.4. Acquiescence and Social Desirability Bias
Methods Acquiescence is the tendency of a respondent to select the “yes” or “agree” option regardless of the content of the question or topic (Heerwegh and Loosveldt 2011). Social desirability is the tendency of respondents to overstate positive behaviors and understate negative ones (Andersen and Mayerl 2017). In the context of the FSANS questions, the socially desirable responses were those corresponding to higher levels of knowledge regarding healthful eating or safe food handling practices. Questions were coded or re-coded such that higher scores represented higher acquiescence and higher social desirability (Table 3).
The hypothesis that RDD (interviewer-administered) fostered higher acquiescence than ABS (self-administered) was assessed by calculating the acquiescence for “battery groups” of questions with either a “yes/no” or on a Likert agree scale, namely battery groups 4, 6 and 7 (Table 3) (Kim et al. 2019). “Don’t know,” blanks, “Neither agree nor disagree,” and “Refused” (RDD only) were excluded from the analysis as they are not informative of acquiescence in any direction. Social desirability bias was assessed on battery groups 2, 4, and 5, and non-battery questions CBQ645, dietcal (self-reported calorie consumption, Table 3), D4 and D11.
To assess if RDD respondents presented higher acquiescence or social desirability bias, the average score (value) for each battery group or question was linearly regressed on mode. Because acquiescence or social desirability may be related to respondent characteristics (Heerwegh and Loosveldt 2011), gender, age, race, education, income, and urbanicity were included as covariates in the model.
Results: As hypothesized, RDD fostered higher acquiescence than ABS web and paper (Table 6). RDD also fostered greater social desirability than ABS for battery group 4, the battery comprising the latent variable Healthy Diet, and dietcal.
4. DISCUSSION AND CONCLUSION
To maintain survey quality, many probability-based surveys, including the FDA Food Safety and Nutrition Survey (FSANS), have transitioned from RDD to ABS methodology. Using the 2019 FSANS survey, this paper provides a thorough cross-mode analytical comparison of sampling and measurement biases between the RDD and ABS (web and paper) modes and serves as a guide to survey researchers, seeking to transition survey modes .
The most notable difference between the RDD and ABS sample compositions is home ownership, with the ABS sample comprised of significantly more homeowners than the RDD sample. Since the early 1990s, renters have been much less likely than homeowners to complete mailed Census questionnaires (Word 1997). The ABS paper option was included to encourage renters to respond to the survey, but they were still underrepresented, suggesting that other strategies to oversample or recruit renters may be warranted in future ABS surveys.
Overall, the transition between RDD and ABS was successful. Latent factor variance equivalence, the highest level of mode measurement equivalence examined, was established for the Food Safety and Food Handling models and partial scalar equivalence was established for the Nutrition Awareness model. This demonstrates that these questions were successfully transitioned from an interview administered telephone mode to a self-administered written survey without changing the meaning of the questions or underlying theoretical concepts the questions were measuring.
As expected, there were some minor differences in mode measurement bias between the RDD and ABS survey modes. Consistent with the literature, RDD respondents were more likely to acquiesce and for one group of questions related to Healthy Diet, RDD respondents were also more likely to provide socially desirable answers (Heerwegh and Loosveldt 2011). We hypothesize that for the Healthy Diet questions, the RDD acquiescence bias and the social desirability bias likely worked in conjunction to contribute to the lower variability observed in the RDD ME Nutrition Awareness model, for which only partial scalar equivalence was established.
The many data quality checks that were implemented before and during data collection, including writing questions in as neutral a manner as possible, conducting cognitive tests of the survey instruments, pretesting all data collection methods, and removing respondents who sped through the survey were helpful in achieving mode equivalence.
Finally, in situations where data cycles differ by survey administration mode and bias(s) is(are) found, a trend analysis may still be conducted as long as remedial actions are taken. One action is to include the cycle or survey mode as an indicator variable in predictive models in order to compare variables of interest after adjusting for mode (i.e., Type 3 or Partial analyses). Another action, in cases where strict scalar or latent factor variance equivalence is not established, i.e., the modes have different precision or variability, survey sampling weights can be further adjusted by giving greater weight to the survey mode with higher precision.
If mode equivalence is not established and remedial actions are not implemented, proceeding with a trend analysis may lead to finding differences over time which are not true differences (i.e., false significance) but are instead due to mode invariance. For example, if a mode exhibits greater precision (as in RDD for the FSANS Nutrition awareness questions), differences may be found due to non-homogeneity of variances (heteroskedasticity) and not true differences in means (Frost 2017).
While there were some minor imbalances between the two survey modes, we find that the FSANS RDD telephone and ABS web and paper modes are acceptably equivalent to justify the transition from RDD to ABS and to maintain continuity in tracking trends over time. Our findings highlight the importance of comprehensively assessing survey biases, so that researchers can feel confident about the overall success of the survey transition while also pinpointing specific questions (or topics) that may require additional work before making trends comparisons. Additionally, for researchers planning new surveys, our findings suggest that ABS web and paper surveys offer many advantages over RDD phone surveys, such as higher response rates and lower tendencies for acquiescence.
Funding
The authors are with the Office of Analytics and Outreach, Center for Food Safety and Applied Nutrition, US Food and Drug Administration. This work was funded by the U.S. Food and Drug Administration, Center for Food Safety and Applied Nutrition.
Acknowledgements
The authors want to thank Jennifer Berktold, PhD, Hyunshik Lee, PhD, Michael Jones, Jonathan Wivagg and supporting staff at Westat for their support during this project.