

Introduction
Due to technical advancements, the amount of audio data vastly increased over the past decades (Fallgren, Malisz, and Edlund 2018). Automatic speech recognition (ASR) automatically transcribes audio into text data which then can be used for analysis (Ghai and Singh 2012). A recent area of application is social science surveys that provide respondents the possibility to answer parts of the survey with voice-recordings (Gavras and Höhne 2022; Gavras et al. 2022; Höhne 2021; Lenzner and Höhne 2022; Revilla, Couper, and Ochoa 2018; Revilla et al. 2020; Revilla and Couper 2021; Ziman et al. 2018). Voice-recordings potentially reduce survey completion time (Revilla et al. 2020) and improve criterion validity (Gavras and Höhne 2022). These studies rely on ASR because it drastically reduces transcription time and cost (Revilla and Couper 2021; Ziman et al. 2018).
However, the transcription and the voice-recording might differ. The accuracy of ASR transcriptions might be low due to longer, shorter, missing, added text, or compound words (Errattahi et al. 2019; Ghannay, Estève, and Camelin 2020). A common measure of ASR accuracy is the word error rate (WER) which is the number of transcription errors divided by the answer length (Kim et al. 2019; Tancoigne et al. 2022). The higher the WER, the worse the transcription. Additionally, the ASR transcription could change the meaning of transcribed words (i.e., validity). Accuracy and validity might differ by context factors and subgroups (e.g., sex and age), which potentially introduces bias in the analysis of open-ended answers. We assume that low accuracy might also deteriorate the validity of the transcription.
This study has two research questions:
RQ1: Does the accuracy of ASR transcriptions differ by subgroups and context factors?
RQ2: Does the validity of ASR transcriptions differ by subgroups and context factors?
Previous research reported on a gender bias in ASR performance due to an overrepresentation of men in the ASR training database (Garnerin, Rossato, and Besacier 2003). Most ASR models are also trained with young people, which potentially reduces ASR performance for the elderly (Pellegrini et al. 2012).
H1: Accuracy and validity are lower for women than for men.
H2: Accuracy and validity are higher for younger than for older respondents.
Context factors such as background noise can reduce ASR performance (Morgan, Wegmann, and Cohen 2013; Rodrigues et al. 2019).
H3: Background noise reduces accuracy and validity.
Research on voice-recordings in surveys is often done in mobile surveys (Revilla et al. 2020; Revilla, Couper, and Ochoa 2018). Voice-recordings can be implemented in web surveys where respondents also answer on PCs, laptops, or tablets. Mobile respondents are more used to voice-recordings than PC or tablet users, which improves ASR performance (Revilla and Couper 2021; Rodrigues et al. 2019). Previous research also indicates that ASR performance decreases with increasing distance between the microphone and the speaker (Renals and Swietojanski 2017; Kim et al. 2019). PC and laptops are therefore potentially more challenging for ASR systems than mobiles due to the need for distant speech recognition.
H4: Smartphone users have a higher accuracy and validity than respondents using other devices.
Social context might affect ASR performance, too. Nonresponse increased in a voice-recording study when respondents felt they were being overheard (Revilla and Couper 2021). Respondents might whisper answers to avoid bystanders’ eavesdropping. At home, respondents may dare to speak louder and can more easily control the volume of background noises. Background noises might also be less diverse than in public places. ASR systems are trained in very controlled conditions and perform worse with diverse background noises or low volume responses (Kalinli et al. 2010; Morgan, Wegmann, and Cohen 2013).
H5: Accuracy and validity is higher for respondents answering the survey from home than for respondents who are not at home.
H6: Accuracy and validity is higher for respondents who are alone during the survey than for respondents who are not alone.
Methods and data
Data
Data were collected in December 2020 by the Longitudinal Internet Studies for the Social Sciences (LISS) panel, a probability online panel of the Dutch population (see https://www.lissdata.nl/about-panel). The goal of the study was to assess whether voice-recording studies are feasible in a probability based mixed-device web panel of the general population. Based on a between-subjects design, respondents were randomly assigned to one of the experimental conditions at the beginning of the survey: written response only, voice-recording only, or choice between written and voice-recording. Since the focus of our analysis was on voice-recordings, we allotted more respondents to the voice-recording and choice conditions than to the written response condition. In total, 661 respondents (19.35%) were assigned to the written response condition, 1,306 respondents (38.26%) were assigned to the voice-recording condition, and 1,449 respondents (42.39%) to the choice condition. In the current study, we focus only on respondents that used the voice-recording option.
Average completion time was 5.0 minutes (median 3.7 minutes). Voice-recordings were collected with the browser-based questfox tool (https://questfox.online/en/questmanagement) that uses Google speech-to-text as the ASR system. Once the respondents submitted their voice-recordings, they could not view or edit their transcribed responses.
The initial data set had 3,416 respondents of which 358 received a voice-recording option as the only answering option or selected voice-recording when given the choice and met technical and legal requirements for answering with voice-recordings. In this study, we only included respondents who completed the survey, provided permission to use audio data, and had a voice-recording as well as the transcribed text. Sample size was reduced further because some responses were unintelligible or it was impossible to distinguish between words in the transcription (>20 words not or incorrectly transcribed, 25 cases) or because respondents had included more than one entry (5 cases).
The final sample had 212 respondents of which 100 were female and 112 male. The average age was 48.79 (SD = 17.43), 54.7% of the respondents had a higher education (higher vocational education or university), and 22.2% of respondents answered the survey on a smartphone. Around a quarter of the respondents were alone when responding to the survey (23.1%) and had background noise in their recordings (25.9%). The majority of respondents filled out the survey at home (97.2%).
It is important to note that the respondents included in the final sample are on average higher educated, younger, and more often male than the respondents who were assigned to the choice condition and opted for a written response instead of a voice-recording (higher education: 37.0%, average age: M =53.2 [SD=18.5], women: 54.0%).
Tested Question
For our analysis, we used voice-recordings to a category-selection probe, a special kind of open-ended question (Willis 2005). The closed question was “In general how would you rate the current state of the economy in the Netherlands?” (English translation). The category-selection probe then asked the respondent to “Please explain why you selected [answer at question mentioned before]” (English translation).
Coding Procedure
We developed a coding schema based on previous research on common ASR error types and sources (Errattahi et al. 2019; Ghannay, Estève, and Camelin 2020). It distinguishes between error types (e.g., error in verbs, nouns) and error sources (e.g., background noise, pronunciation errors) and assessed whether the content/meaning of the response changed due to the transcription.
Responses were available as voice-recordings and automatically transcribed text. Both response types were coded for discrepancies by a human coder and partly (19 respondents) recoded by a second coder. The interrater agreement was 86.4%, which is good given the complexity of the coding schema and task (Gisev, Bell, and Chen 2013). All coding disagreements were resolved and integrated into the final data set. We analyzed the data with SPSS 25.
Measures
Dependent variables
Our dependent variable for the accuracy analysis is WER, a count variable of ASR transcription errors by response length in words. A transcription with a WER of .25 means that 25% of the words would need to be altered (via substitutions, deletions, or insertions) to perfectly match the reference transcript. WER can exceed 1.00 because words can appear in the transcription but not in the voice-recording (e.g., voice-recording: ‘rentes’; transcription: ‘rente is’). WER is a good measure for speech analytics if the WER is below 25% (Park et al. 2008). For the validity analysis, we used a binary variable that indicates whether the meaning of the response was changed due to a transcription error or not.
Independent variables
We used sex (reference category: male), age, background noise (reference: no background noise), self-reported mobile usage (reference: no mobile), location of the respondent during the study (reference: at home), and social context (reference: alone) as independent variables. We included education as a binary control variable (reference: high education).
We assessed all assumptions of our regression models. We removed an extreme outlier with a WER exceeding 1000%. We tested for multicollinearity and found very low VIF values (1.04 to 1.14). In addition, non-linear effects of age were tested and found to be non-significant for both models.
Analytical Strategy
For the accuracy analysis, we regressed a count variable with log of the answer length (number of words) as an offset variable in a negative binomial regression model to obtain the WER. Negative binomial regression accounted for the overdispersion present in our data (Hilbe 2014). For the validity analysis, we calculated a logistic regression with change of meaning (yes/no) as the dependent variable.
Results
Accuracy
WER ranged from 0 to 3.33 and the average WER was 0.20 (SD=0.36), which means that it is an appropriate measure of speech analytics for our study. The histogram (see Figure 1) shows the frequencies of word error rates.

When compared to the Poisson model (AIC = 1184.19, BIC = 1211.04), a negative binomial model is indeed more appropriate for our data (AIC = 936.23, BIC = 966.43). The estimate of the dispersion coefficient B negative binomial was 0.951 (SD = 0.15), indicating that there is a small amount of overdispersion present (see Table 1, Model Accuracy). The negative binomial regression model was statistically significant (7)=21.26, p=.003). Only background noise significantly predicted WER (p<.001). Responses with background noise had a 2.08-times higher WER than responses without background noise. Neither sex, age, mobile usage, location, nor social context significantly predicted WER. Education was also not significant.
Validity
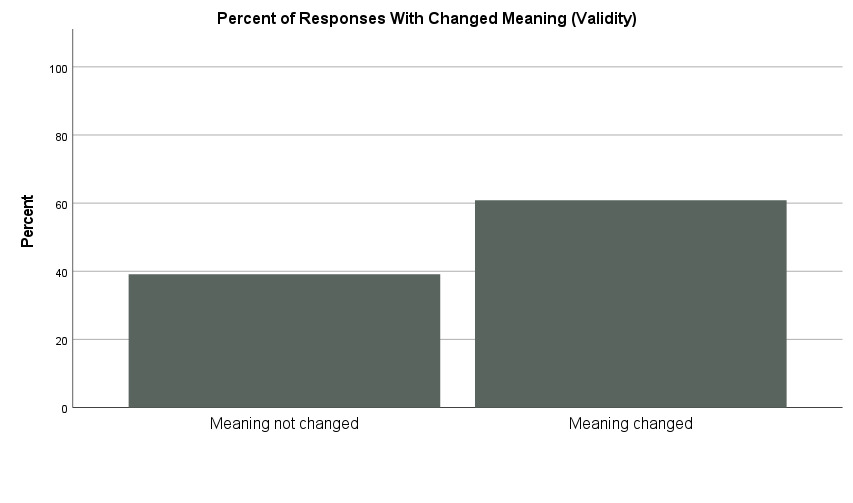
In 60.8% of the analyzed responses, the meaning of at least one word changed due to the ASR transcription (see Figure 2).
The logistic regression model (see Table 1, Model Validity) was statistically significant (7)=16.70, p=.019) and 66.5% of respondents were correctly classified (Nagelkerke R2 =.103). Responses with background noise had 2.21-times higher odds that the meaning of the response changed than responses without background noise (p=.030). Additionally, respondents who were alone had lower odds of a changed meaning than respondents who were not alone (OR: 0.43, p=.017). None of the other predictors were significant. The sample had enough (80%) power to distinguish between an 0.188 difference in proportion, e.g., 0.5 versus 0.688.
Discussion
We have evaluated the impact of group characteristics and context factors on the accuracy and validity of ASR transcriptions of voice-recordings in social science web surveys.
We were concerned that performance differences introduce a bias in the analysis of open-ended questions. Accuracy and validity did not significantly differ by sex and age (H1 and H2 not confirmed). Although this is contrary to previous research (Garnerin, Rossato, and Besacier 2003; Pellegrini et al. 2012), this is good news because we did not find evidence for bias in the ASR transcriptions for these subgroups. The likely explanation for our null findings is that the performance of ASR systems improved since previous research has been conducted (Kim et al. 2019).
Additionally, we assessed different context factors that potentially deteriorate ASR performance. Contrary to our hypotheses, we found no significant effect for smartphone usage (H4 not confirmed), which is good news for the implementation of voice-recordings in mixed device surveys. Location (i.e., not at home) was also not a significant predictor in both regression models (H5). The most likely explanation for this null finding is that the sample did not contain sufficient respondents that filled out the survey outside of their home. Whereas accuracy was not significantly influenced by social context (i.e., not alone), being alone significantly improved the validity of ASR transcriptions (H6 partly confirmed). The optimistic interpretation regarding accuracy would be that ASR performance is nowadays performing well in different locations and social contexts. This is in line with current ASR research that reports sinking WER rates in various conditions and languages due to training effects (Kim et al. 2019; Proksch, Wratil, and Wäckerle 2019; Tancoigne et al. 2022). The more pessimistic interpretation would be that situations might be more complex than assumed. For example, being at home could mean a calm surrounding but could also be quite noisy in the case of a family with young children. While social context did not matter regarding accuracy, validity was affected, indicating that ASR systems might perform differently depending on whether respondents are alone or not. One explanation would be that respondents dare to speak louder when they are alone, which improves ASR performance (Morgan, Wegmann, and Cohen 2013). This also underlines that an assessment of ASR performance should not only rely on WER but should be supplemented by some content analysis (see also Proksch, Wratil, and Wäckerle 2019). In line with previous research (Morgan, Wegmann, and Cohen 2013; Rodrigues et al. 2019), background noise significantly reduced accuracy and validity (H3 confirmed). When coding the voice-recordings, we also coded what type of background noise appeared and found that background noises are rarely due to social settings (e.g., café, workplace sounds) or outside locations (e.g., traffic noise) but due to, for example, television sounds or white noise.
Several of these background noises can potentially be reduced by a proactive survey design. For example, respondents could be informed about the voice-recording in the invitation letter and provided with some advice regarding optimal recording conditions to fill out the survey (e.g., switch off TV, optimal set-up of the microphone). During the survey, precise feedback on microphone performance could be given with targeted advice on how to resolve potential issues. It is possible that improved noise cancellation technology might reduce the impact of the background noise in the future.
Even when the remaining issues with ASR performance are resolved, several challenges for the implementation of voice-recordings in web surveys remain. In our study, only a few respondents show a preference to record their response instead of typing it, and the respondents who are willing to record or who opt for this option are slightly younger, higher educated and more often men than women. This difference might even be more pronounced in a cross-sectional survey design. Our respondents were members of the LISS panel and are therefore used to answering a web survey, sometimes also in nontraditional response formats and tasks (e.g., collection of biomarkers, Avendano 2010). Previous research revealed that voice-recordings potentially reduce survey completion time (Revilla et al. 2020) and can improve criterion validity (Gavras and Höhne 2022). However, to reach its full potential the willingness to do voice-recordings needs to be increased and potential biasing effects of its implementations need to be addressed.
Limitations and Future Research
We assessed the performance of one ASR system (Google speech-to-text) with a question on the economy. Further research could investigate different topics (e.g., sensitive topics) and performance differences of ASR systems (e.g., YouTube, Microsoft Azure) across groups and context factors.
Lead author’s contact details
Katharina Meitinger, Department of Methods & Statistics, Utrecht University, Padualaan 14, 3584 CH Utrecht, The Netherlands. Email: k.m.meitinger@uu.nl
Acknowledgments
This research was supported by the Social Sciences and Humanities Research Council of Canada under grant (SSHRC # 435-2013-0128) and (SSHRC #435-2021-0287). We are thankful for the feedback and helpful suggestions made by the Survey Practice reviewers and editors.